LAMBADA Dataset Papers With Code
Von einem Mystery-Man-Autor
Last updated 08 Juli 2024

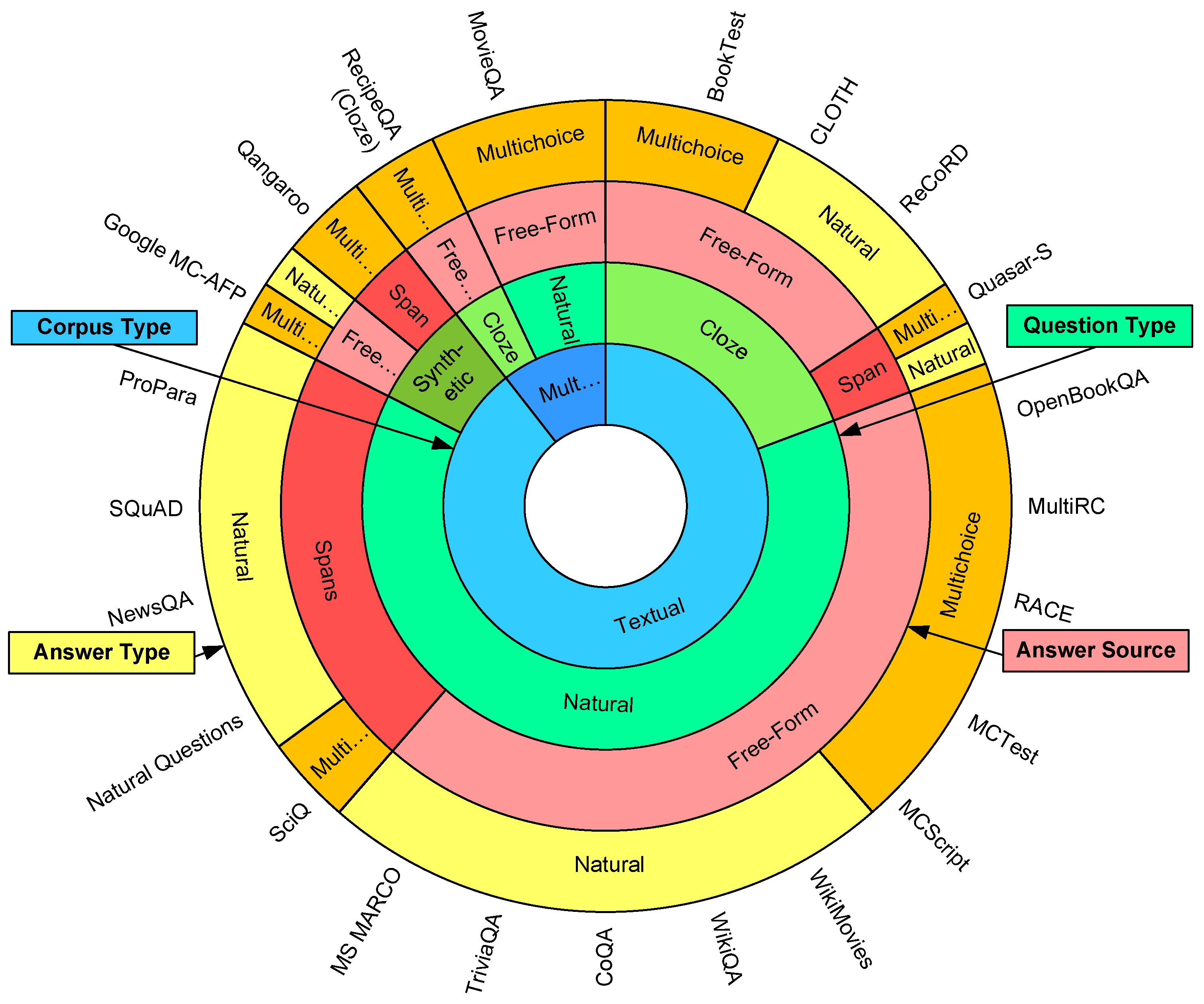
The LAMBADA (LAnguage Modeling Broadened to Account for Discourse Aspects) benchmark is an open-ended cloze task which consists of about 10,000 passages from BooksCorpus where a missing target word is predicted in the last sentence of each passage. The missing word is constrained to always be the last word of the last sentence and there are no candidate words to choose from. Examples were filtered by humans to ensure they were possible to guess given the context, i.e., the sentences in the passage leading up to the last sentence. Examples were further filtered to ensure that missing words could not be guessed without the context, ensuring that models attempting the dataset would need to reason over the entire paragraph to answer questions.

omniglot TensorFlow Datasets
Applied Sciences, Free Full-Text

A Repository of Conversational Datasets

Applied Sciences, Free Full-Text

Text Augmentation in Python with NLPAUG, by Marc Bolle

Introducing S3 Object Lambda – Use Your Code to Process

Phenaki: Variable Length Video Generation From Open Domain Textual

Two minutes NLP — Keeping track of information and the LAMBADA

BIG-bench Benchmark (LAMBADA)
Machine Learning Datasets

Satlas Dataset Papers With Code
für dich empfohlen
 Lambada - Single - Album by Serocee - Apple Music14 Jul 2023
Lambada - Single - Album by Serocee - Apple Music14 Jul 2023 Lambada Rotten Tomatoes14 Jul 2023
Lambada Rotten Tomatoes14 Jul 2023 Lagoa – Lambada Suave (Vinyl) - Discogs14 Jul 2023
Lagoa – Lambada Suave (Vinyl) - Discogs14 Jul 2023 Lambada Kaoma Sheet music for Piano (Solo) Easy14 Jul 2023
Lambada Kaoma Sheet music for Piano (Solo) Easy14 Jul 2023 Lambada - Kaoma14 Jul 2023
Lambada - Kaoma14 Jul 2023 Lambada, Юлия Даймонд - Qobuz14 Jul 2023
Lambada, Юлия Даймонд - Qobuz14 Jul 2023 Lambada Dances at Rs 2000/per person in New Delhi14 Jul 2023
Lambada Dances at Rs 2000/per person in New Delhi14 Jul 2023 Not Without Our Daughters: Lambada Women Fight Infanticide and14 Jul 2023
Not Without Our Daughters: Lambada Women Fight Infanticide and14 Jul 2023 Lambada (with solo) - Eb score Sheet music for Saxophone alto (Solo)14 Jul 2023
Lambada (with solo) - Eb score Sheet music for Saxophone alto (Solo)14 Jul 2023 LEARN LAMBADA - ZoukEssence14 Jul 2023
LEARN LAMBADA - ZoukEssence14 Jul 2023
Sie können auch mögen
 SCHEIBENABZIEHER GUMMI ABZIEHER Wischer Auto LKW Alu14 Jul 2023
SCHEIBENABZIEHER GUMMI ABZIEHER Wischer Auto LKW Alu14 Jul 2023 Action Figure Spider Man Keychain Captain America Keyring Bag Pendant Avengers Car Key Ring Wholesale Spiderman Toy Boy Kid Gift14 Jul 2023
Action Figure Spider Man Keychain Captain America Keyring Bag Pendant Avengers Car Key Ring Wholesale Spiderman Toy Boy Kid Gift14 Jul 2023 Alpina Feine Farben Farbenführer kaufen bei OBI14 Jul 2023
Alpina Feine Farben Farbenführer kaufen bei OBI14 Jul 2023 MSW Seilwinde Handseilwinde 450 kg Bootswinde Anhänger PKW14 Jul 2023
MSW Seilwinde Handseilwinde 450 kg Bootswinde Anhänger PKW14 Jul 2023 ECTIVE SI 5 Wechselrichter 12V 230V 500W reiner Sinus Inverter14 Jul 2023
ECTIVE SI 5 Wechselrichter 12V 230V 500W reiner Sinus Inverter14 Jul 2023 Soffitte LED 9W 3000K 38x480mm S1914 Jul 2023
Soffitte LED 9W 3000K 38x480mm S1914 Jul 2023 Unterlegscheibe groß 10,5 Schraube M10 VA14 Jul 2023
Unterlegscheibe groß 10,5 Schraube M10 VA14 Jul 2023 Set mit 2 H7-LED-Lampen, Anti-Beschlag-Lichter, DC 12 V, 950 lm, reinweiß, 6000 K, LED-Lampen, Tagfahrlicht, als Ersatz für Halogen H714 Jul 2023
Set mit 2 H7-LED-Lampen, Anti-Beschlag-Lichter, DC 12 V, 950 lm, reinweiß, 6000 K, LED-Lampen, Tagfahrlicht, als Ersatz für Halogen H714 Jul 2023 Buy Long Satin Bonnet Sleep Cap,Black Extra Large Silk Bonnet for Natural Hair, Bonnets for Women Night Sleep,Wide Elastic Band, Very Soft & Comfortable Online at Low Prices in India - .in14 Jul 2023
Buy Long Satin Bonnet Sleep Cap,Black Extra Large Silk Bonnet for Natural Hair, Bonnets for Women Night Sleep,Wide Elastic Band, Very Soft & Comfortable Online at Low Prices in India - .in14 Jul 2023 Vollgummiband, ca 9,50 Meter x 20 x 2 mm - Gummifritz24de14 Jul 2023
Vollgummiband, ca 9,50 Meter x 20 x 2 mm - Gummifritz24de14 Jul 2023